This third article of the mathematical journey through open source, takes you through the functional power of bench calculator.
After going through the basic programming on bench calculator, here’s the time to explore its functional power. As mentioned earlier, we can do functions in bench calculator. Unlike C, it has built-in functions, though the standard math functions and the user-defined functions are similar to as in C.
Built-in Functions
Complete list of bc‘s built-in functions is:
- length(expr) – returns the number of significant digits in expr
- read() – reads a number from standard input in the base dictated by the ibase variable
- scale(expr) – returns the number of digits after the decimal point in expr
- sqrt(expr) – returns the positive square root of expr, given that expr is non-negative
Here’s a sample execution of the above functions:
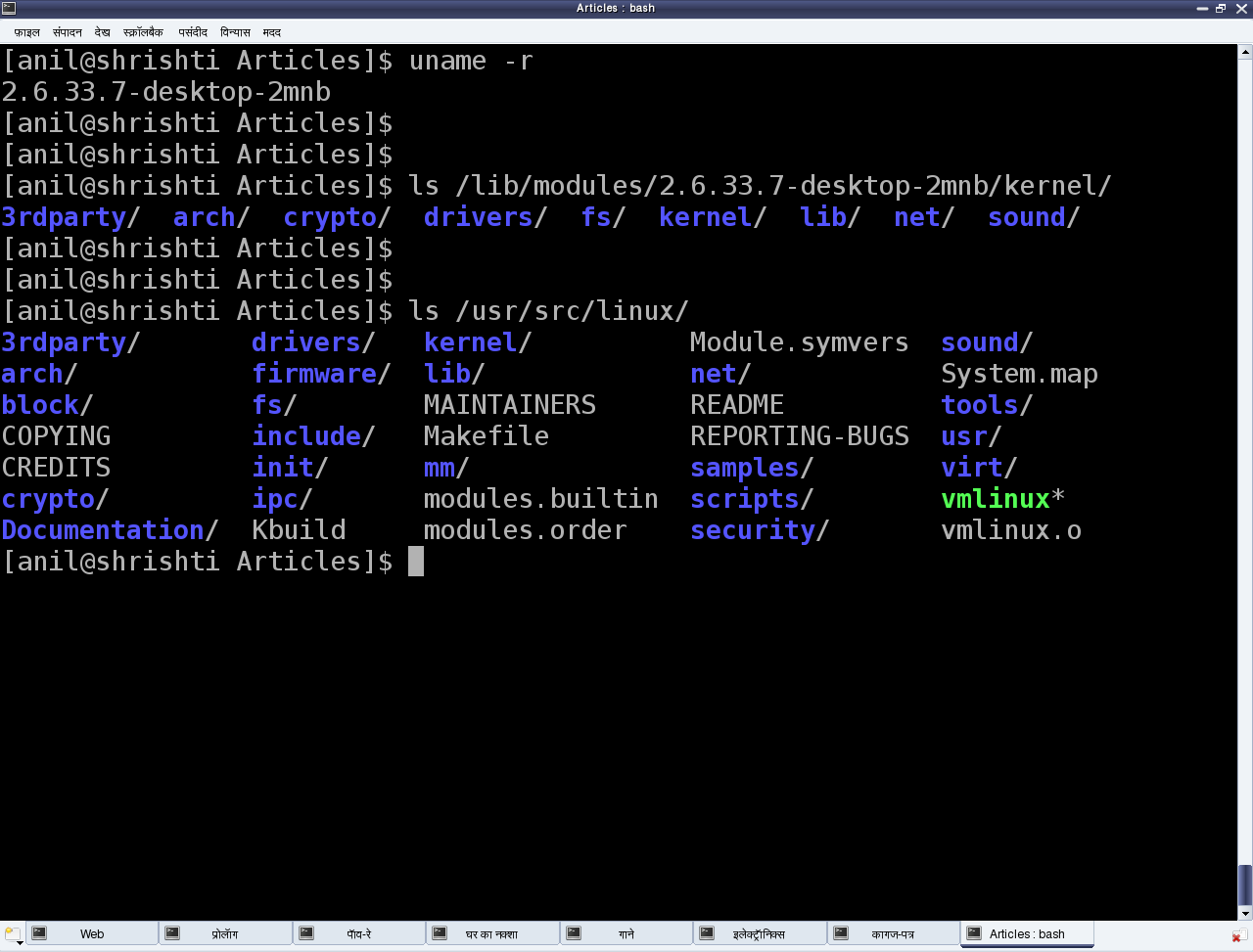
$ bc -ql
length(000023.450) # Number of significant digits
5
scale(000023.450) # Number of digits after the decimal
3
sqrt(2) # Square root of 2
1.41421356237309504880
sqrt(-1) # Square root of -1 is an error
Runtime error (func=(main), adr=4): Square root of a negative number
ibase=2 # Changing the input base to 2
x=read() # Wait to read the input in binary and then display
1100 # This is the input
x # Display the read value in the default output base 10
12
quit # Get out
$
Is that the complete list of built-in functions? But no talk of the previously used print. The reason is that print is not a function – didn’t you notice the missing () with print. print is actually a statement in bc, like if, for, … and the syntax of print is: print <list>, where <list> is a comma separated list of strings and expressions
If you have not yet got the hang of this word expression, it is a statement of numbers and variables operated with the various operators and functions.
Standard Math Functions
When bc is invoked with -l option, the math library gets loaded along with. And the following 6 math functions, also get available to use:
- s(x) – returns sine of x, x is radians
- c(x) – returns cosine of x, x is radians
- a(x) – returns arctangent (in radians) of x
- l(x) – returns the natural logarithm (base e) of x
- e(x) – returns the value of e raised to the power of x
- j(n, x) – Bessel function of integer order n of x
All these functions operate with the scale dictated by the built-in variable scale. By default, scale is set to 20. Here’s a sample execution:
$ bc -ql
scale # Show the current scale
20
pi=4*a(1) # Calculate pi as tan-1(1) is pi / 4
pi # Show the value approx. to 20 decimals
3.14159265358979323844
s(pi/3) # Calculate sine of 60° - should sqrt(3)/2
.86602540378443864675
sqrt(3)/2 # value for comparison – note the approx. error
.86602540378443864676
c(pi/3) # Calculate sine of 60° - should be 0.5
.50000000000000000001
l(1) # log(1)
0
e(1) # Value of e1 approx. to 20 decimals
2.71828182845904523536
quit # Get out
$
This all sounds too geeky and mathematical – all going over the head. Okay, let’s forget about that and do some simple stuff. Let’s write our own simple functions – yes user-defined functions.
User-defined functions
Here is how we write a user-defined function (to add two numbers) in bc:
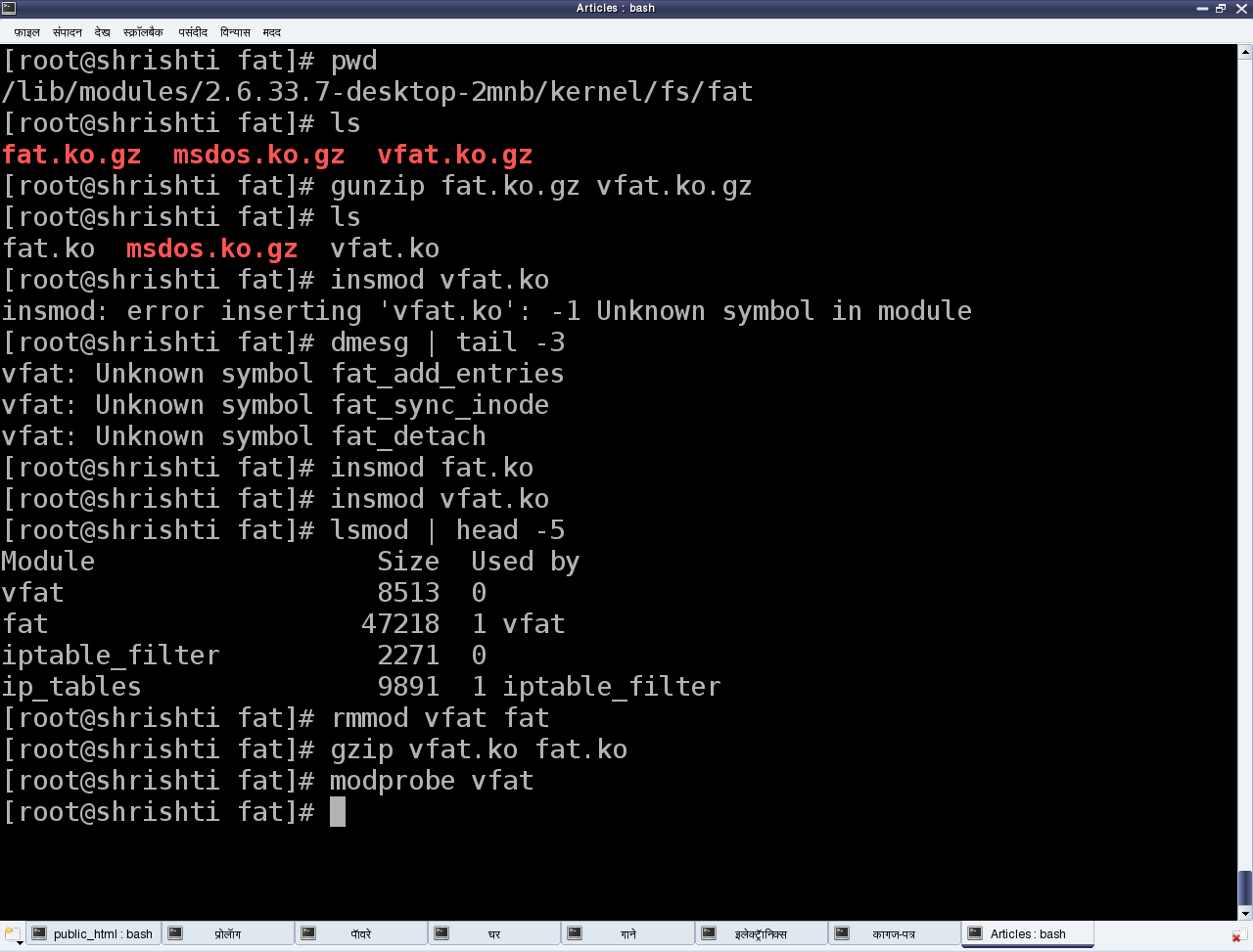
$ bc -ql
define add(x, y) {
return (x + y)
}
add(3, add(4, 5)) # Lets add 3 with the sum of 4 & 5
12
quit # Get out
$
Given that, the factorial code from our previous learnings can be converted into a function as follows (say in functions.bc):
define factorial(n) {
product = 1
for (current_num = 1; current_num <= n; current_num += 1)
{
product *= current_num
}
return product
}
And then, we can use that function as follows:
$ bc -ql functions.bc # Load the functions while invoking bc
factorial(10) # Compute the factorial of 10
3628800
quit # Get out
$
As now, we have factorial, we can even calculate the series of e, i.e. 1 + 1/1! + 1/2! + …, say upto 1/20! for a good enough approximation. Here’s how it would go
$ bc -ql functions.bc # Load the functions while invoking bc
exp=1
for (i = 1; i <= 20; i++)
{
exp += (1/factorial(i))
}
exp # Display the computed value of e
2.71828182845904523525
e(1) # Compare with the standard math function
2.71828182845904523536
quit # Get out
$
And as in C, if we need a function only to do actions and not return anything, void is the way.
$ bc -ql
define void designer_print(v) {
print "---{", v, "}---"
}
designer_print(100) # Print 100 with the designs
---{100}---
quit # Get out
$
With all these fundamentals of functions in bc, next we would dive into its recursive functional power.