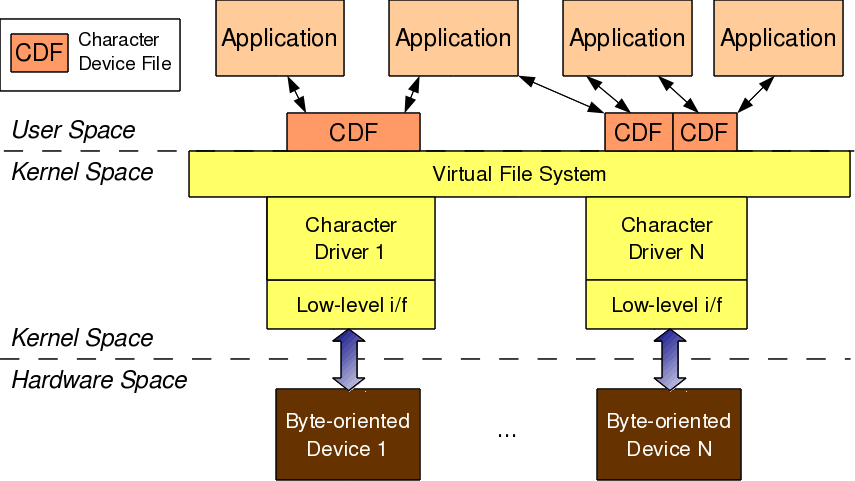
This sixth article, which is part of the series on Linux device drivers, is continuation of the various concepts of character drivers and their implementation, dealt with in the previous two articles.
<< Fifth Article
So, what was your guess on how would Shweta crack the nut? Obviously, using the nut cracker named Pugs. Wasn’t it obvious? <Smile> In our previous article, we saw how Shweta was puzzled with reading no data, even after writing into the /dev/mynull character device file. Suddenly, a bell rang – not inside her head, a real one at the door. And for sure, there was the avatar of Pugs.
“How come you’re here?”, exclaimed Shweta. “After reading your tweet, what else? Cool that you cracked your first character driver all on your own. That’s amazing. So, what are you up to now?”, said Pugs. “I’ll tell you on the condition that you do not become a spoil sport”, replied Shweta. “Okay yaar, I’ll only give you pointers”. “And that also, only if I ask for”. “Okie”. “I am trying to decode the working of character device file operations”. “I have an idea. Why don’t you decode and explain me your understanding?”. “Not a bad idea”. With that, Shweta tailed the dmesg log to observe the printk‘s output from her driver. Alongside, she opened her null driver code on her console, specifically observing the device file operations my_open, my_close, my_read, and my_write.
static int my_open(struct inode *i, struct file *f)
{
printk(KERN_INFO "Driver: open()\n");
return 0;
}
static int my_close(struct inode *i, struct file *f)
{
printk(KERN_INFO "Driver: close()\n");
return 0;
}
static ssize_t my_read(struct file *f, char __user *buf, size_t len, loff_t *off)
{
printk(KERN_INFO "Driver: read()\n");
return 0;
}
static ssize_t my_write(
struct file *f, const char __user *buf, size_t len, loff_t *off)
{
printk(KERN_INFO "Driver: write()\n");
return len;
}
Based on the earlier understanding of return value of the functions in kernel, my_open() and my_close() are trivial. Their return types being int and both of them returning zero, meaning success. However, the return types of both my_read() and my_write() are not int, but ssize_t. On further digging through kernel headers, that turns out to be signed word. So, returning a negative number would be a usual error. But a non-negative return value would have an additional meaning. For read it would be number of bytes read, and for write it would be number of bytes written.
Reading the device file
For understanding this in detail, the complete flow has to be re-looked at. Let’s take read first. So, when the user does a read onto the device file /dev/mynull, that system call comes to the virtual file system (VFS) layer in the kernel. VFS decodes the <major, minor> tuple & figures out that it need to redirect it to the driver’s function my_read(), registered with it. So from that angle, my_read() is invoked as a request to read, from us – the device driver writers. And hence, its return value would indicate to the requester – the user, as to how many bytes is he getting from the read request. In our null driver example, we returned zero – meaning no bytes available or in other words end of file. And hence, when the device file is being read, the result is always nothing, independent of what is written into it.
“Hmmm!!! So, if I change it to 1, would it start giving me some data?”, Pugs asked in his verifying style. Shweta paused for a while – looked at the parameters of the function my_read() and confirmed with a but – data would be sent but it would be some junk data, as the my_read() function is not really populating the data into the buf (second parameter of my_read()), provided by the user. In fact, my_read() should write data into buf, according to len (third parameter of my_read()), the count in bytes requested by the user.
To be more specific, write less than or equal to len bytes of data into buf, and the same number be used as the return value. It is not a typo – in read, we ‘write’ into buf – that’s correct. We read the data from (possibly) an underlying device and then write that data into the user buffer, so that the user gets it, i.e. reads it. “That’s really smart of you”, expressed Pugs with sarcasm.
Writing into the device file
Similarly, the write is just the reverse procedure. User provides len (third parameter of my_write()) bytes of data to be written, into buf (second parameter of my_write()). my_write() would read that data and possibly write into an underlying device, and accordingly return the number of bytes, it has been able to write successfully. “Aha!! That’s why all my writes into /dev/mynull have been successful, without being actually doing any read or write”, exclaimed Shweta filled with happiness of understanding the complete flow of device file operations.
Preserving the last character
That was enough – Shweta not giving any chance to Pugs to add, correct or even speak. So, Pugs came up with a challenge. “Okay. Seems like you are thoroughly clear with the read/write funda. Then, here’s a question for you. Can you modify these my_read() and my_write() functions such that whenever I read /dev/mynull, I get the last character written into /dev/mynull?”
Confident enough, Shweta took the challenge and modified the my_read() and my_write() functions as follows, along with an addition of a static global character:
static char c;
static ssize_t my_read(struct file *f, char __user *buf, size_t len, loff_t *off)
{
printk(KERN_INFO "Driver: read()\n");
buf[0] = c;
return 1;
}
static ssize_t my_write(
struct file *f, const char __user *buf, size_t len, loff_t *off)
{
printk(KERN_INFO "Driver: write()\n");
c = buf[len – 1];
return len;
}
“Almost there, but what if the user has provided an invalid buffer, or what if the user buffer is swapped out. Wouldn’t this direct access of user space buf just crash and oops the kernel”, pounced Pugs. Shweta not giving up the challenge, dives into her collated material and figures out that there are two APIs just to ensure that the user space buffers are safe to access and then update them, as well. With the complete understanding of the APIs, she re-wrote the above code snippet along with including the corresponding header <asm/uaccess.h>, as follows, leaving no chance for Pugs to comment:
#include <asm/uaccess.h>
static char c;
static ssize_t my_read(struct file *f, char __user *buf, size_t len, loff_t *off)
{
printk(KERN_INFO "Driver: read()\n");
if (copy_to_user(buf, &c, 1) != 0)
return -EFAULT;
else
return 1;
}
static ssize_t my_write(
struct file *f, const char __user *buf, size_t len, loff_t *off)
{
printk(KERN_INFO "Driver: write()\n");
if (copy_from_user(&c, buf + len – 1, 1) != 0)
return -EFAULT;
else
return len;
}
Then, Shweta repeated the usual build and test steps as follows:
- Build the modified null driver (.ko file) by running make.
- Load the driver using insmod.
- Write into /dev/mynull, say using echo -n “Pugs” > /dev/mynull
- Read from /dev/mynull using cat /dev/mynull (Stop using Ctrl+C)
- Unload the driver using rmmod.
Summing up
On cat‘ing /dev/mynull, the output was a non-stop infinite sequence of ‘s’, as my_read() gives the last one character forever. So, Pugs intervenes and presses Ctrl+C to stop the infinite read, and tries to explain, “If this is to be changed to ‘the last character only once’, my_read() needs to return 1 the first time and zero from second time onwards. This can be achieved using the off (fourth parameter of my_read())”. Shweta nods her head to support Pugs’ ego.
Seventh Article >>
Add-on
And here’s the modified read using the off:
static ssize_t my_read(struct file *f, char __user *buf, size_t len, loff_t *off)
{
printk(KERN_INFO "Driver: read()\n");
if (*off == 0)
{
if (copy_to_user(buf, &c, 1) != 0)
return -EFAULT;
else
{
(*off)++;
return 1;
}
}
else
return 0;
}