This ninth article, which is part of the series on Linux device drivers, talks about the typical ioctl() implementation and usage in Linux.
“Get me a laptop and tell me about the experiments on the x86-specific hardware interfacing conducted in yesterday’s Linux device drivers’ laboratory session, and also about what’s planned for the next session”, cried Shweta, exasperated at being confined to bed and not being able to attend the classes. “Calm down!!! Don’t worry about that. We’ll help you make up for your classes. But first tell us what happened to you, so suddenly”, asked one of her friends, who had come to visit her in the hospital. “It’s all the fault of those chaats, I had in Rohan’s birthday party. I had such a painful food poisoning that led me here”, blamed Shweta. “How are you feeling now?”, asked Rohan sheepishly. “I’ll be all fine – just tell me all about the fun with hardware, you guys had. I had been waiting to attend that session and all this had to happen, right then”.
Rohan sat down besides Shweta and summarized the session to her, hoping to soothe her. That excited her more and she starting forcing them to tell her about the upcoming sessions, as well. They knew that those would be to do something with hardware, but were unaware of the details. Meanwhile, the doctor comes in and requests everybody to wait outside. That was an opportunity to plan and prepare. And they decided to talk about the most common hardware controlling operation: the ioctl(). Here is how it went.
Introducing an ioctl()
Input-output control (ioctl, in short) is a common operation or system call available with most of the driver categories. It is a “one bill fits all” kind of system call. If there is no other system call, which meets the requirement, then definitely ioctl() is the one to use. Practical examples include volume control for an audio device, display configuration for a video device, reading device registers, … – basically anything to do with any device input / output, or for that matter any device specific operations. In fact, it is even more versatile – need not be tied to any device specific things but any kind of operation. An example includes debugging a driver, say by querying of driver data structures.
Question is – how could all these variety be achieved by a single function prototype. The trick is using its two key parameters: the command and the command’s argument. The command is just some number, representing some operation, defined as per the requirement. The argument is the corresponding parameter for the operation. And then the ioctl() function implementation does a “switch … case” over the command implementing the corresponding functionalities. The following had been its prototype in Linux kernel, for quite some time:
int ioctl(struct inode *i, struct file *f, unsigned int cmd, unsigned long arg);
Though, recently from kernel 2.6.35, it has changed to the following:
long ioctl(struct file *f, unsigned int cmd, unsigned long arg);
If there is a need for more arguments, all of them are put in a structure and a pointer to the structure becomes the ‘one’ command argument. Whether integer or pointer, the argument is taken up as a long integer in kernel space and accordingly type cast and processed.
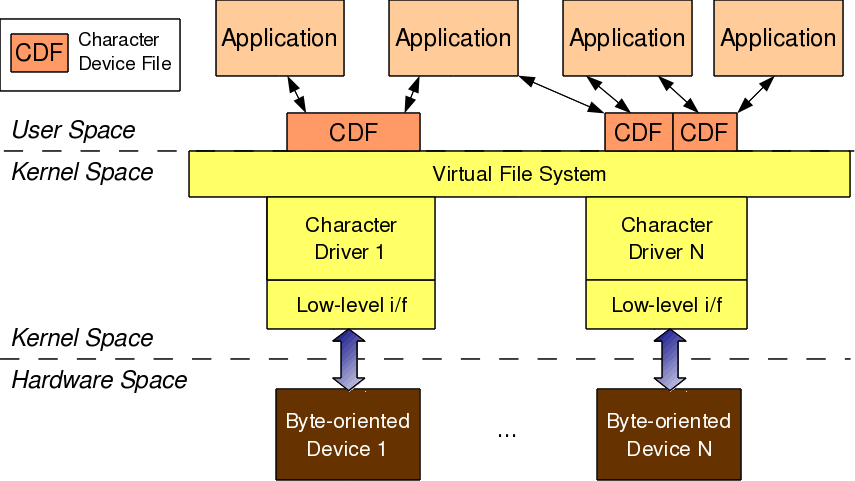
ioctl() is typically implemented as part of the corresponding driver and then an appropriate function pointer initialized with it, exactly as with other system calls open(), read(), … For example, in character drivers, it is the ioctl or unlocked_ioctl (since kernel 2.6.35) function pointer field in the struct file_operations, which is to be initialized.
Again like other system calls, it can be equivalently invoked from the user space using the ioctl() system call, prototyped in <sys/ioctl.h> as:
int ioctl(int fd, int cmd, ...);
Here, cmd is the same as implemented in the driver’s ioctl() and the variable argument construct (…) is a hack to be able to pass any type of argument (though only one) to the driver’s ioctl(). Other parameters will be ignored.
Note that both the command and command argument type definitions need to be shared across the driver (in kernel space) and the application (in user space). So, these definitions are commonly put into header files for each space.
Querying the driver internal variables
To better understand the boring theory explained above, here’s the code set for the “debugging a driver” example mentioned above. This driver has 3 static global variables status, dignity, ego, which need to be queried and possibly operated from an application. query_ioctl.h defines the corresponding commands and command argument type. Listing follows:
#ifndef QUERY_IOCTL_H
#define QUERY_IOCTL_H
#include <linux/ioctl.h>
typedef struct
{
int status, dignity, ego;
} query_arg_t;
#define QUERY_GET_VARIABLES _IOR('q', 1, query_arg_t *)
#define QUERY_CLR_VARIABLES _IO('q', 2)
#endif
Using these, the driver’s ioctl() implementation in query_ioctl.c would be:
static int status = 1, dignity = 3, ego = 5;
#if (LINUX_VERSION_CODE < KERNEL_VERSION(2,6,35))
static int my_ioctl(struct inode *i, struct file *f, unsigned int cmd,
unsigned long arg)
#else
static long my_ioctl(struct file *f, unsigned int cmd, unsigned long arg)
#endif
{
query_arg_t q;
switch (cmd)
{
case QUERY_GET_VARIABLES:
q.status = status;
q.dignity = dignity;
q.ego = ego;
if (copy_to_user((query_arg_t *)arg, &q,
sizeof(query_arg_t)))
{
return -EACCES;
}
break;
case QUERY_CLR_VARIABLES:
status = 0;
dignity = 0;
ego = 0;
break;
default:
return -EINVAL;
}
return 0;
}
And finally the corresponding invocation functions from the application query_app.c would be as follows:
#include <stdio.h>
#include <sys/ioctl.h>
#include "query_ioctl.h"
void get_vars(int fd)
{
query_arg_t q;
if (ioctl(fd, QUERY_GET_VARIABLES, &q) == -1)
{
perror("query_apps ioctl get");
}
else
{
printf("Status : %d\n", q.status);
printf("Dignity: %d\n", q.dignity);
printf("Ego : %d\n", q.ego);
}
}
void clr_vars(int fd)
{
if (ioctl(fd, QUERY_CLR_VARIABLES) == -1)
{
perror("query_apps ioctl clr");
}
}
Complete code of the above mentioned three files is included in the folder QueryIoctl, where the required Makefile is also present. You may download its tar-bzipped file as query_ioctl_code.tar.bz2, untar it and then, do the following to try out:
- Build the ‘query_ioctl’ driver (query_ioctl.ko file) and the application (query_app file) by running make using the provided Makefile.
- Load the driver using insmod query_ioctl.ko.
- With appropriate privileges and command-line arguments, run the application query_app:
- ./query_app # To display the driver variables
- ./query_app -c # To clear the driver variables
- ./query_app -g # To display the driver variables
- ./query_app -s # To set the driver variables (Not mentioned above)
- Unload the driver using rmmod query_ioctl.
Defining the ioctl() commands
“Visiting time is over”, came calling the security guard. And all of Shweta’s visitors packed up to leave. Stopping them, Shweta said, “Hey!! Thanks a lot for all this help. I could understand most of this code, including the need for copy_to_user(), as we have learnt earlier. But just a question, what are these _IOR, _IO, etc used in defining the commands in query_ioctl.h. You said we could just use numbers for the same. But you are using all these weird things”. Actually, they are usual numbers only. Just that, now additionally, some useful command related information is also encoded as part of these numbers using these various macros, as per the Portable Operating System Interface (POSIX) standard for ioctl. The standard talks about the 32-bit command numbers being formed of four components embedded into the [31:0] bits:
- Direction of command operation [bits 31:30] – read, write, both, or none – filled by the corresponding macro (_IOR, _IOW, _IOWR, _IO)
- Size of the command argument [bits 29:16] – computed using sizeof() with the command argument’s type – the third argument to these macros
- 8-bit magic number [bits 15:8] – to render the commands unique enough – typically an ASCII character (the first argument to these macros)
- Original command number [bits 7:0] – the actual command number (1, 2, 3, …), defined as per our requirement – the second argument to these macros
“Check out the header <asm-generic/ioctl.h> for implementation details”, concluded Rohan while hurrying out of the room with a sigh of relief.
Notes:
- The intention behind the POSIX standard of encoding the command is to be able to verify the parameters, direction, etc related to the command, even before it is passed to the driver, say by VFS. It is just that Linux has not yet implemented the verification part.